Database Selection Guide: Choosing the Right Tool for Every Job (2025)

Picking the right database isn't about finding the "best" one—it's about matching your workload, scale, and team constraints. This guide breaks down when to use what, with real performance numbers and practical examples.
The Big Picture: Database Types & Their Sweet Spots
Relational (SQL)
Best for: Complex queries, ACID transactions, structured data Examples: PostgreSQL, MySQL, Aurora
Document (NoSQL)
Best for: Flexible schemas, rapid prototyping, content management Examples: MongoDB, DynamoDB
Key-Value
Best for: Caching, sessions, real-time features Examples: Redis, DynamoDB (single-table design)
Graph
Best for: Relationships, recommendations, fraud detection Examples: Neo4j, Amazon Neptune
Time-Series
Best for: Metrics, IoT data, financial data Examples: InfluxDB, TimescaleDB
PostgreSQL: The Swiss Army Knife
When to choose: Complex queries, strong consistency, full-text search, JSON workloads
Performance Profile
- Read: 15-30K QPS (single instance)
- Write: 5-15K QPS (single instance)
- Storage: Petabyte-scale with partitioning
- Latency: 1-5ms (local), 10-50ms (cross-region)
Customization Superpowers
-- Custom data types
CREATE TYPE mood AS ENUM ('sad', 'ok', 'happy');
-- Custom operators
CREATE OPERATOR @@ (
LEFTARG = text,
RIGHTARG = text,
FUNCTION = textsearch
);
-- Extensions ecosystem
CREATE EXTENSION pg_trgm; -- fuzzy search
CREATE EXTENSION postgis; -- geospatial
CREATE EXTENSION timescaledb; -- time-series
Real-world Use Cases
- Stripe: Handles billions in transactions with complex financial queries
- Instagram: User data, relationships, and content metadata
- Discord: Messages, guilds, and user preferences
Gotchas:
- Single-writer bottleneck (use read replicas)
- Vacuum maintenance required
- Memory-hungry for large working sets
MongoDB: Document Flexibility Champion
When to choose: Rapid prototyping, content management, catalog data
Performance Profile
- Read: 10-50K QPS (sharded)
- Write: 5-25K QPS (sharded)
- Storage: Horizontal scaling to hundreds of TBs
- Latency: 1-10ms (same region)
Schema Evolution Made Easy
// Start simple
{ name: "John", email: "john@example.com" }
// Evolve without migrations
{
name: "John",
email: "john@example.com",
profile: {
avatar: "https://...",
preferences: { theme: "dark" }
},
tags: ["developer", "postgres-fan"]
}
Indexing for Speed
// Compound indexes for complex queries
db.users.createIndex({ "profile.location": 1, "lastActive": -1 });
// Text search
db.articles.createIndex({ title: "text", content: "text" });
// Geospatial
db.stores.createIndex({ location: "2dsphere" });
Best practices:
- Design for your query patterns first
- Use aggregation pipelines for analytics
- Embed related data to reduce joins
Redis: The Speed Demon
When to choose: Caching, sessions, real-time leaderboards, pub/sub
Performance Profile
- Operations: 100K-1M+ OPS/sec
- Latency: Sub-millisecond
- Memory: Up to 768GB (ElastiCache)
Data Structures Playground
// Strings (caching)
SET user:1001 '{"name":"John","email":"john@example.com"}'
EXPIRE user:1001 3600
// Hashes (user sessions)
HSET session:abc123 user_id 1001 last_seen 1640995200
HGET session:abc123 user_id
// Sets (tags, followers)
SADD user:1001:followers 2002 3003 4004
SINTER user:1001:followers user:2002:followers // mutual friends
// Sorted Sets (leaderboards)
ZADD leaderboard 1500 "player1" 1200 "player2"
ZREVRANGE leaderboard 0 9 WITHSCORES // top 10
// Streams (event sourcing)
XADD events * action "user_signup" user_id 1001
XREAD COUNT 10 STREAMS events $
Scaling patterns:
- Redis Cluster: Horizontal partitioning
- Sentinel: High availability with failover
- Persistence: RDB snapshots + AOF logs
DynamoDB: Serverless Scale Monster
When to choose: Unpredictable traffic, millisecond latency, serverless architectures
Performance Profile
- Read: Unlimited (with auto-scaling)
- Write: Unlimited (with auto-scaling)
- Latency: Single-digit milliseconds
- Storage: Virtually unlimited
Single-Table Design Philosophy
// One table, multiple entity types
{
"PK": "USER#1001",
"SK": "PROFILE",
"name": "John",
"email": "john@example.com"
},
{
"PK": "USER#1001",
"SK": "ORDER#2023-001",
"amount": 99.99,
"status": "shipped"
},
{
"PK": "CATEGORY#electronics",
"SK": "PRODUCT#laptop-001",
"name": "MacBook Pro",
"price": 1999
}
Access Patterns First
- Get user profile:
PK = USER#1001, SK = PROFILE - Get user orders:
PK = USER#1001, SK begins_with ORDER# - Get products by category:
PK = CATEGORY#electronics
Trade-offs:
- ✅ Infinite scale, predictable performance
- ❌ Limited query flexibility, eventual consistency by default
Aurora: PostgreSQL/MySQL on Steroids
When to choose: Large-scale applications requiring SQL with cloud-native benefits
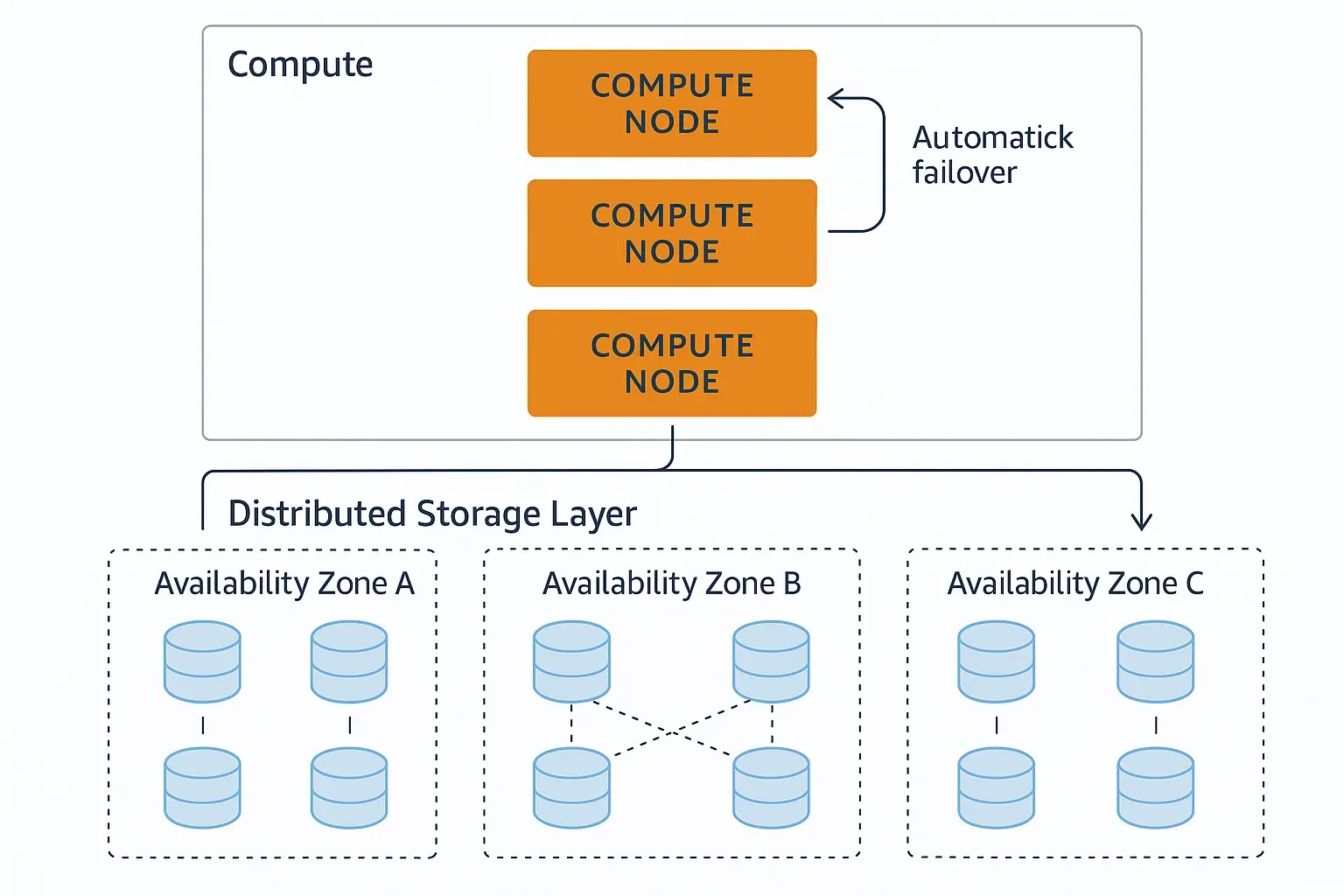
How Aurora Works Under the Hood
Storage Architecture Revolution
Traditional databases couple compute and storage. Aurora separates them:
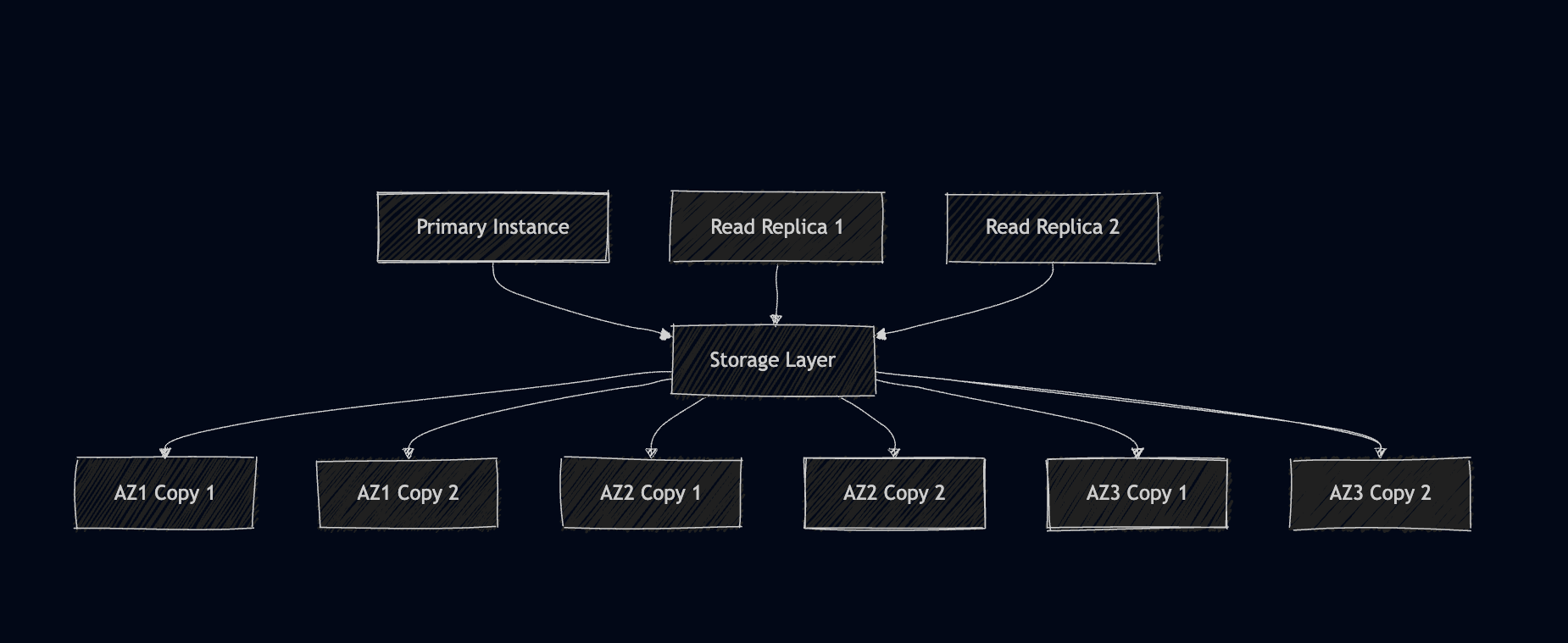
The Magic: Log-Based Replication
Instead of shipping full data pages, Aurora only sends log records:
Traditional: Page (16KB) × 6 replicas = 96KB network traffic
Aurora: Log record (100-200 bytes) × distributed = ~1KB
Performance Numbers
- Read throughput: 5x faster than stock PostgreSQL
- Write throughput: 3x faster than stock MySQL
- Failover: Sub-30 second automatic recovery
- Backup: Continuous, point-in-time recovery to any second
Aurora Serverless v2: Pay-per-Request Scaling
# Scales from 0.5 to 128 ACUs automatically
MinCapacity: 0.5 # ~1GB RAM
MaxCapacity: 16 # ~32GB RAM
SecondsUntilAutoPause: 300
Cost optimization:
- Dev/staging: Pause when idle
- Production: Right-size min/max capacity
- Cross-region: Use Global Database for <1s RPO
When Aurora Makes Sense
- Unicorn startups: Need SQL but planning for massive scale
- Enterprise: Migrating from Oracle/SQL Server
- Global apps: Multi-region with consistent performance
- Analytics: Reader endpoints for heavy reporting
Aurora vs RDS:
- Aurora: 2-3x cost, 3-5x performance, better availability
- RDS: Lower cost, simpler setup, good for <100GB workloads
Decision Matrix: Matching Database to Use Case
| Use Case | Primary Choice | Alternative | Why |
|---|---|---|---|
| E-commerce catalog | PostgreSQL | MongoDB | Complex pricing queries + JSON flexibility |
| User sessions | Redis | DynamoDB | Sub-ms latency required |
| Analytics warehouse | PostgreSQL + TimescaleDB | BigQuery | Time-series + complex aggregations |
| Chat/messaging | MongoDB | PostgreSQL | Document-heavy, flexible schemas |
| Financial transactions | PostgreSQL | Aurora PostgreSQL | ACID compliance + audit trails |
| IoT telemetry | InfluxDB | DynamoDB | Time-series optimized |
| Social graph | Neo4j | PostgreSQL | Relationship queries |
| Content management | MongoDB | PostgreSQL + JSONB | Schema evolution needs |
| Real-time leaderboards | Redis | DynamoDB | Sorted sets + atomic updates |
| Global serverless app | DynamoDB | Aurora Serverless | Auto-scaling + multi-region |
Performance Optimization Patterns
PostgreSQL: Query Tuning
-- Index for common queries
CREATE INDEX CONCURRENTLY idx_orders_user_date
ON orders(user_id, created_at DESC)
WHERE status = 'active';
-- Partial indexes for sparse data
CREATE INDEX idx_premium_users
ON users(last_login)
WHERE plan = 'premium';
-- Monitor slow queries
SELECT query, mean_exec_time, calls
FROM pg_stat_statements
ORDER BY mean_exec_time DESC
LIMIT 10;
MongoDB: Aggregation Pipeline
// Efficient pipeline with early filtering
db.orders.aggregate([
{ $match: { created_at: { $gte: lastWeek } } }, // Filter first
{ $group: {
_id: "$user_id",
total: { $sum: "$amount" },
count: { $sum: 1 }
}},
{ $sort: { total: -1 } },
{ $limit: 100 }
]);
DynamoDB: Hot Partition Avoidance
// Bad: Sequential IDs create hot partitions
"PK": "USER#000001"
"PK": "USER#000002"
// Good: Distributed keys
"PK": "USER#" + hash(userId) % 100 + "#" + userId
Multi-Database Architectures (Polyglot Persistence)
Real applications often need multiple databases:
Netflix Architecture Pattern
├── User Service (Cassandra) # User profiles, preferences
├── Catalog Service (MySQL) # Movie metadata, categories
├── Viewing Service (DynamoDB) # Watch history, positions
├── Search Service (Elasticsearch) # Content discovery
└── Cache Layer (Redis) # Hot data, sessions
Event-Driven Consistency
// User updates profile in PostgreSQL
await userService.updateProfile(userId, profile);
// Publish event to event bus
await eventBus.publish('user.profile.updated', {
userId,
profile,
timestamp: new Date()
});
// Other services react and update their views
searchService.reindexUser(userId); // Update Elasticsearch
cacheService.invalidate(`user:${userId}`); // Clear Redis
Database Migration Strategies
Zero-Downtime Migration Pattern
- Dual-write: Write to both old and new databases
- Background sync: Copy historical data in batches
- Validation: Compare data integrity between systems
- Switch reads: Route read traffic to new database
- Cleanup: Remove dual-write logic and old database
Schema Evolution (PostgreSQL)
-- Safe column addition
ALTER TABLE users ADD COLUMN phone VARCHAR(20);
-- Safe index creation (non-blocking)
CREATE INDEX CONCURRENTLY idx_users_phone ON users(phone);
-- Risky: Changing column types (requires downtime)
-- Use application-level migration instead
Monitoring and Observability
Key Metrics to Track
- Throughput: QPS, TPS
- Latency: p50, p95, p99
- Error rate: Failed queries, timeouts
- Resource utilization: CPU, memory, disk I/O
- Connection pool: Active connections, wait time
PostgreSQL Monitoring
-- Connection stats
SELECT state, count(*)
FROM pg_stat_activity
GROUP BY state;
-- Lock monitoring
SELECT query, state, wait_event
FROM pg_stat_activity
WHERE wait_event IS NOT NULL;
-- Table statistics
SELECT schemaname, tablename, n_tup_ins, n_tup_upd, n_tup_del
FROM pg_stat_user_tables;
Cost Optimization Strategies
PostgreSQL on AWS
- RDS: $0.017/hour (t3.micro) → $2.40/hour (r5.4xlarge)
- Aurora: $0.024/hour (t3.medium) → $3.84/hour (r5.4xlarge)
- Storage: $0.10/GB/month (RDS gp2) vs $0.10/GB/month (Aurora)
Optimization tips:
- Use read replicas for read-heavy workloads
- Schedule non-critical instances (dev/staging)
- Reserved instances for predictable workloads (up to 60% savings)
DynamoDB Cost Model
Read Cost = (RCU × $0.00013) + (Storage × $0.25/GB)
Write Cost = (WCU × $0.00065)
Example:
- 1M reads/day = ~12 RCU = $0.046/month
- 100K writes/day = ~1.2 WCU = $0.023/month
- 1GB storage = $0.25/month
Total: ~$0.32/month for small app
The Future: Emerging Database Trends
Serverless-First Databases
- Aurora Serverless v2: True per-second billing
- DynamoDB: Already serverless, adding PartiQL support
- PlanetScale: Serverless MySQL with branching
Multi-Cloud and Edge
- CockroachDB: Distributed SQL across regions
- FaunaDB: Serverless, globally distributed
- Supabase: PostgreSQL with real-time subscriptions
AI-Optimized Databases
- Vector databases: Pinecone, Weaviate for embeddings
- Graph + AI: Neo4j with machine learning pipelines
Quick Decision Checklist
Starting a new project?
- Small app, simple queries → PostgreSQL
- Need real-time features → PostgreSQL + Redis
- Flexible schema, rapid iteration → MongoDB
- Serverless-first → DynamoDB
Scaling an existing app?
- PostgreSQL hitting limits → Aurora PostgreSQL
- MongoDB sharding complexity → Consider PostgreSQL partitioning
- Need multi-region → DynamoDB Global Tables or Aurora Global
Performance problems?
- Slow queries → Add appropriate indexes
- Hot cache misses → Redis for frequently accessed data
- Write bottlenecks → Shard or use async patterns
- Complex analytics → Dedicated OLAP database
Budget constraints?
- Predictable traffic → Reserved instances
- Spiky traffic → Serverless options
- High availability needs → Aurora (worth the premium)
Remember: The best database is the one your team can operate effectively. Master one well before adding complexity.



